Used some deflicker in Resolve to clean it up. Next step would be to create a mask (maybe using depth maps) to do loopback cleanup. In this sample the left arm (on the right side of the video) could definitely be cleaned up with in-painting so it would be cool to script that with a depth-map to inpaint just that section. Way above my paygrade I am just leech reaping the benefits of all you kind open source making souls.
take a look at the console output, it will give you a hint. For me it mostly fails because of memory issues. In that case use less ControlNets and/or enable the Low Vram mode.
I think it's a really great work but I have a problem after trying it. I use recommandation settings to render my frames, then the frame2 and frame3 have a bad color degradation compared with frame1, even if they are same pictures. Fortunately after frame3 there is no longer color degradation. It makes the step1 style transfer become no use, is this an unfixed bug?
I appreciate the desire to tip but unfortunately Paypal is the only thing I have setup that can accept tips like that (unless you deal with crypto or something where I could make a keypair quickly). No need to concern yourself with tipping me though. People have been more generous than I expected already (especially the people that came here after the PromptMuse video dropped)
I havent tested with any 2.X since ControlNet was released for it, but it works great on every 1.5 model I have tested with although I havent tested pix2pix at all
The solution of CGJackB did it for me. Got the error with 330 files but not with 30. I found the lenght check that is throwing the error in line 38 of the multiframe script. Any idea what the limitation here is or how to make it able to run more files at once?
This works pretty well in the beginning. But inside the tunnel it is too dark to give the ControlNet enough info for a consistent animation. I will try again with another sequence inside the tunnel, after the camera adapted to the darkness.
Unfortunately I have a problem with the tool, although I can not understand the cause.
I think I have tried all imaginable combinations for the last 3 days and no matter what settings I use, the frames become more and more "noisy" or "pixelated" over time.
See the attached pictures.
First image is from frame 0
Second image is from frame 10
Has anyone encountered this problem before or have any idea what is causing it?
the Allow other script to control this extension is on. Please find attached the screenshot of the settings in the img2img tab. The controlNet settings are written on the right side in the text. I used the models mlsd, depth-leres, hed and segmentation.
FYI: AntiBurn is off. It also doesn`t matter if I use all, some or none StabeNet Moduls, the issue is allways there.
Thank you for your great work! It is a novel and impressive idea.
I am unfamiliar with SD webui as I do not have a local PC to run it. But technically, I am wondering how this method can use two kinds of image conditions (ControlNet input and inpainting mask). Is the basic inpainting model (like official sd-v1.5-inpainting) works well on the official ControlNet, even if the ControlNet model is not pretrained based on that inpainting model?
An inpainting-mask layer isn't implemented into the script yet but it's planned for an upcoming update so you can do stuff like only modifying areas of the video. As for how ControlNet works on various models, it seems to work on dreamboothed models just fine, so all the ones people download should work. I ran my tests on RealisticVision1.4 just because I like that model in general but I haven't tested if inpainting-specific models do better or worse.
Thank you for your reply! I guess a branch for the inpainting mask is already used in the current version, as the frame-wise mask is used as p.image_mask input. In addition, I just found that the webui will guess the model type by counting the inputs' dimensions. The program seems to automatically choose the inpainting version as the base model. I am wondering that did you download all checkpoints of RealisticVision1.4, including the inpainting version? Thanks!
I do have the inpainting model for RV1.4 and I used that version a couple times, but I generally just used the normal version for the tests and I haven't compared the inpainting vs non-inpainting models yet. As for the inpainting mask I think I misunderstood what you meant. It does use an image mask in order to do the processing, but there isn't currently a way to upload custom masks for the frames themselves and I thought you were asking about that.
help, my images are very dark,I have tried many methods, such as replacing ckpt or vae, checking "Settings: Apply color correction to img2img results to match original colors", and reducing resolution. But the image hasn't changed anything.
What are the settings that you're using? I suspect it might be too low of a denoising strength but it would be helpful to see the settings as a whole in order to help
I usually use 1.0 denoise strength but for most images I'd suggest going with 0.75-1.0, so keep it high. With the black background it also could be more prone to darkening from either the color correction or the loopback (i.e. denoising below 1)
Hello! How can I use your add-on on a remote server? When you click "add files" the download window opens from my computer, but the program itself is running on another server and the files are not uploaded there.
As for the batches, I have been debating how they should work with it. I'm working on a system where you can have it generate multiple versions of each new frame then have it try to pick the best one at each iteration to get better consistency. I believe that would probably be the most useful way to use batch processing for it but it's not quite ready yet.
probably nothing as complex or computationally expensive as that but I'm looking to perhaps use some of the control_net preprocessors to help reduce details like stray hairs from manifesting or disappearing randomly, as well as some color checking to keep color-flickering to a minimum
Hi, I can't figure out why the script give me only the first frame, the subject don't change pose like is not following the controlNet, I followed the guide step by step, and here are my settings. What m I doing wrong? I also clciked on upload guide frames, select all frames and then open.
Did you allow the script to control the extension in Settings/ControlNet? You need to enable the option and do a complete restart of A1111 UI, as it seems to set the permissions on startup. Had the same problem, doing that made it work for me.
In this experiment I used the Dreamshaper model that generates pretty nice illustrations. The ControlNet 'depth' alone, however, is not so great. As we can see it struggles with the details when the fingers are near the mouth and so the AI starts to create a horrible act of chewing finger nails.
Looks great! I think the best method would be if you used something like blender and had it render perfect depthmaps instead of using the preprocessor, but I haven't actually tested that yet. I have heard a lot about https://toyxyz.gumroad.com/l/ciojz for that kind of thing but I have never tried it myself and I don't know how it would work for animations. I would like to implement the ability to add multiple controlnet inputs rather than just the guiding frames but the issue is that, as far as I'm aware, I can only change the "control_net_input_image" property to impact them all at once and I cannot set them individually with a script.
I figured out my problem. I run Automatic1111 on a Windows machine, to utilize the fast Nvidia card, but my main machine is a Mac, so I have Automatic1111 set to listen mode. When trying to run the script from my Mac it only ever processes the first frame. If I run the script on the actual Windows machine, everything is fine. Keep up the great work, this is cool!
Even I struggle with speed on it. I plan to upgrade my GPU but I dont see why someone couldnt bring this to their google colab or runpod or anything else like that to run it remotely on faster hardware
This is incredible, Xanthius singlehandedly created a far better product than gen-1 from runaway and they have like a team of researchers... I bet they are copying that Idea right now!
Thanks! That's big praise, especially for a project that has currently only taken 3 and a half days to develop. There's still a long way to go with this
Hey! Looks great! What setting did you use? Denoise strnght, ControlNet setting and script settings. I am trying for 2 days without success... I would really appreciate some help:) Thanks!
I sent my img2img render of the first frame to img2img. - img2img Denoising 0.95 - ControlNet 'depth' (+preprocessor depth) with default settings - script settings: init denoise=1, Third Frame Img=FirstGen, Color Correction On, Loopback Source=Previous Frame - prompt: a chimpanzee walks through the desert
I upload a sequence of 512x512 images - there's no visual feedback, yet. So it's just a 'trust me bro' thing for now ;)
Don't put anything in the ControlNet image upload - this is where the script puts your frames automatically.
Make sure that the mentioned ControlNet setting is enabled that allows the script to control the extension.
Had the same issue. It was working after I restarted A1111 completely (not just 'reload ui') and checked 'Allow other script to control this extension' again - it was unchecked after the restart. So maybe your script just does not have the permission (yet) to drop the frames into ControlNet.
I see. I havent really been testing much with multi-ControlNet for the sake of speed, but I'm guessing that it would come down to the weights for the two controlnet layers. This tool is still extremely early so a lot of testing needs to be done to figure out the best way to get the right results.
There are a few youtubers who have said they are working on tutorials for it. It has only been published for around 2 days, so many things aren't fully worked out or understood yet, even by me, so they may take a bit of time to experiment and figure it out for the models and embeddings they may use it with then publish their video. Each model seems to need different settings
the animations should just be in alphabetical order but it doesnt need a specific naming scheme. It could be causing your problem though. I never put anything into the controlNet input manually. I just leave the image sections blank on those and let it get auto-filled
I'm having the same trouble as finefin – just rendering after rendering of the first frame – and I've still got the problem of it rendering 3-up strips, even after installing v.72. Should there be some feedback in the GUI after I upload my images? It doesn't show if they've uploaded or not. I've tried both Safari and Chrome on a Mac. This looks like an amazing achievement! Excited to get it working!
The images are not uploading and not showing up in the gui. I end up with 'animations' of one single image. Images are 512x512 and named image001.png, image002.png etc. What am I missing?
Are you talking about the upload of the guide frames? At the moment the UI doesn't give visual feedback on that, but I would like to add something to show that the files were successfully uploaded (perhaps a number indicating how many frames are currently uploaded)
As for the image outputs, the individual frames should appear in the "stable-diffusion-webui\outputs\img2img-images" folder and should be named along the lines of "Frame-0001" and the spritesheets should be saved to "stable-diffusion-webui\outputs\img2img-grids" with names such as "grid-0001" although the filename for this is subject to change in future updates.
Both the spritesheet and the individual frames should properly output to the GUI and do on my end. Does nothing get returned for you or what exactly are you getting?
the image you linked requires permission to view but that issue largely comes down to settings such as denoise strength, ColorCorrection, and Third Frame Image.
It should directly output the spritesheet and the frames. You're the second person to have it output the 3-panel images instead and I'm not sure why some people have that happen
The individual files should be named along the lines of Frame-XXXX and will be located in your default folder for images. The spritesheet will be in the default folder for grids
Here's a gif I generated while writing and testing the fix:
im getting this any idea why ?? and is control net suppose to be on the same wauy in the img2img page ? can you show pics of both setups as pics the whole page ?
the "object of type 'NoneType' has no len()" error usually occurs if you forgot to give it the animation guide frames.
To provide the guide frames for the script, press the "Upload Guide Frames" button located just above the slider and select the frames of your animation
If you have the frames from a guiding video then you can put those in. It's just the input for ControlNet, so you could also put in a processed set of images for your choice of model (openpose, hed, depth, etc...) with the preprocessor disabled.
My guess would be the controlnet settings. Check how your controlnet mask looks when only working with the first frame to get an idea of what may be wrong and what it's picking up. Perhaps pick a different controlnet model or just fix the settings on the one you are using.
Thank you for your fast response. I tride different ControlNet models (canny, hed, depth, normal), weight (0.3,0.5,0.9 or even 1.6), preprocessor on/off and 3 sets of guide frames with no luck. Only this happens:
What does the original video look like? it's hard to keep a consistent background unless the original background has enough detail to be picked up with ControlNet. For that reason I expect many people will just generate with a greenscreen or something then superimpose it onto a background.
It sure does, I just suck at naming. In the future I plan to make a much better and more robust animation tool based on this which will probably be an extension instead of just a script and I intend to call that one Xanimate (combining my screen-name and the world Animate) which I think it at least better
This is crazy!!! I thought that kind of coherence between frames would require an entirely new iteration of stable diffusion. I never thought this would be possible by a single person, this is huge! And you didn't even use denoising post production tricks to achieve that ... that's like 500 IQ move! 😄 well done!
← Return to tool
Comments
Log in with itch.io to leave a comment.
take a look at the console output, it will give you a hint. For me it mostly fails because of memory issues. In that case use less ControlNets and/or enable the Low Vram mode.
I think it's a really great work but I have a problem after trying it. I use recommandation settings to render my frames, then the frame2 and frame3 have a bad color degradation compared with frame1, even if they are same pictures. Fortunately after frame3 there is no longer color degradation. It makes the step1 style transfer become no use, is this an unfixed bug?
Hello,
Is there a different way to tip you? I don't use PayPal.
Thanks!
I appreciate the desire to tip but unfortunately Paypal is the only thing I have setup that can accept tips like that (unless you deal with crypto or something where I could make a keypair quickly). No need to concern yourself with tipping me though. People have been more generous than I expected already (especially the people that came here after the PromptMuse video dropped)
Well, except a sincere thank you and a virtual high-five then 🤚
Glad to hear others have been generous
what category to put the plug-in in, i use the web version of StableDiffusion
I can't really make it work, recorded a sceen capture.
https://capture.dropbox.com/QB4hVnHsGhGAjB4B
I havent tested it with pix2pix and I dont know how inpainting works for that model, have you tried it with any other models?
Yes, 1.5 is the other one I have and I still can't make it work.
Do I strictly need SD 2.0?
I havent tested with any 2.X since ControlNet was released for it, but it works great on every 1.5 model I have tested with although I havent tested pix2pix at all
Tks, I'll try again without pix2pix.
Hello, I heep getting this error: TypeError: object of type 'NoneType' has no len()
Any idea of what it can be? Tks
I have only seen that error when guide frames aren't uploaded from the interface
I was getting this error when I was trying to do 120 frames. I tried fewer frames, like 35, to see if that would work and it did.
So try using fewer frames to see.
The solution of CGJackB did it for me. Got the error with 330 files but not with 30. I found the lenght check that is throwing the error in line 38 of the multiframe script. Any idea what the limitation here is or how to make it able to run more files at once?
Did you figure it out since? I have 250 images and it throws the same error
Here's what the source material looks like: http://twitter.com/finefingames/status/1388535835985948681?cxt=HHwWksC93Y3_iMUmA...
And here you can download a 614 frame sequence of this clip as 512x512px PNGs and try for yourself: http://finefin.com/tmp/TunnelSequence-614frames-512x512.zip
Unfortunately I have a problem with the tool, although I can not understand the cause.
I think I have tried all imaginable combinations for the last 3 days and no matter what settings I use, the frames become more and more "noisy" or "pixelated" over time.
See the attached pictures.
First image is from frame 0

Second image is from frame 10Has anyone encountered this problem before or have any idea what is causing it?
Is the "Allow other script to control this extension" setting in ControlNET ON? Show us your settings in the img2img tab.
the Allow other script to control this extension is on. Please find attached the screenshot of the settings in the img2img tab. The controlNet settings are written on the right side in the text. I used the models mlsd, depth-leres, hed and segmentation.
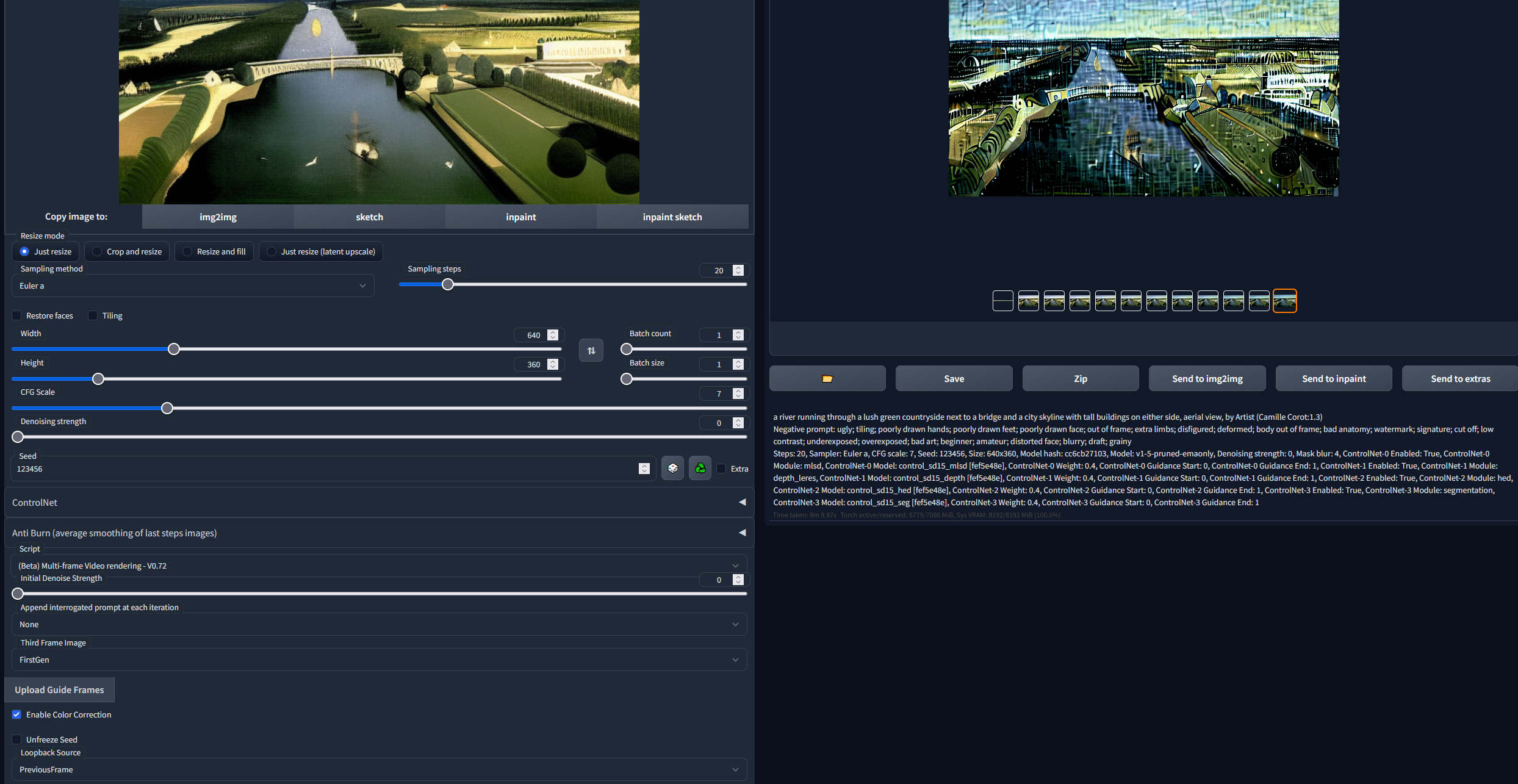
FYI:
AntiBurn is off.
It also doesn`t matter if I use all, some or none StabeNet Moduls, the issue is allways there.
I have an GeForce GTX 1080
Denoising strength should be around 1.
check this vid:
Thanks for your reply. I think, this was my problem. Wasn`t quite shure, which denoise strength should be set to 0. First tests looking promising.
I discovered that removing the background helps with maintaining consistency. I'm using this extension:
https://github.com/AUTOMATIC1111/stable-diffusion-webui-rembg
A short video about it:
Thank you for your great work! It is a novel and impressive idea.
I am unfamiliar with SD webui as I do not have a local PC to run it. But technically, I am wondering how this method can use two kinds of image conditions (ControlNet input and inpainting mask). Is the basic inpainting model (like official sd-v1.5-inpainting) works well on the official ControlNet, even if the ControlNet model is not pretrained based on that inpainting model?
An inpainting-mask layer isn't implemented into the script yet but it's planned for an upcoming update so you can do stuff like only modifying areas of the video. As for how ControlNet works on various models, it seems to work on dreamboothed models just fine, so all the ones people download should work. I ran my tests on RealisticVision1.4 just because I like that model in general but I haven't tested if inpainting-specific models do better or worse.
Thank you for your reply! I guess a branch for the inpainting mask is already used in the current version, as the frame-wise mask is used as p.image_mask input. In addition, I just found that the webui will guess the model type by counting the inputs' dimensions. The program seems to automatically choose the inpainting version as the base model. I am wondering that did you download all checkpoints of RealisticVision1.4, including the inpainting version? Thanks!
I do have the inpainting model for RV1.4 and I used that version a couple times, but I generally just used the normal version for the tests and I haven't compared the inpainting vs non-inpainting models yet. As for the inpainting mask I think I misunderstood what you meant. It does use an image mask in order to do the processing, but there isn't currently a way to upload custom masks for the frames themselves and I thought you were asking about that.
help, my images are very dark,I have tried many methods, such as replacing ckpt or vae, checking "Settings: Apply color correction to img2img results to match original colors", and reducing resolution. But the image hasn't changed anything.
What are the settings that you're using? I suspect it might be too low of a denoising strength but it would be helpful to see the settings as a whole in order to help
"FirstGen" and "InputFrame".I have tried 0.2~0.9 of Denoise Strength
I usually use 1.0 denoise strength but for most images I'd suggest going with 0.75-1.0, so keep it high. With the black background it also could be more prone to darkening from either the color correction or the loopback (i.e. denoising below 1)
I use a white background,I tried 1.0 denoise strength still incorrect. Looks like it's lost color
still incorrect. Looks like it's lost color
what are all the settings and prompt you used?
Hello! How can I use your add-on on a remote server? When you click "add files" the download window opens from my computer, but the program itself is running on another server and the files are not uploaded there.
For future updates, is it possible for your script to have batch img2img as part of the process as well?
Looks fantastic!
As for the batches, I have been debating how they should work with it. I'm working on a system where you can have it generate multiple versions of each new frame then have it try to pick the best one at each iteration to get better consistency. I believe that would probably be the most useful way to use batch processing for it but it's not quite ready yet.
A content-aware system? Wow, that'd be fantastic. Is that something like what SD/DD Warpfusion does on their implementation, ie optical flow?
probably nothing as complex or computationally expensive as that but I'm looking to perhaps use some of the control_net preprocessors to help reduce details like stray hairs from manifesting or disappearing randomly, as well as some color checking to keep color-flickering to a minimum
i put the script in correct folder, the mult frame appears in my scripts tag, but the controls of the script dosent... i need to seetings something?
what happens when you run it?
Hi, I can't figure out why the script give me only the first frame, the subject don't change pose like is not following the controlNet, I followed the guide step by step, and here are my settings. What m I doing wrong? I also clciked on upload guide frames, select all frames and then open.
And this is the result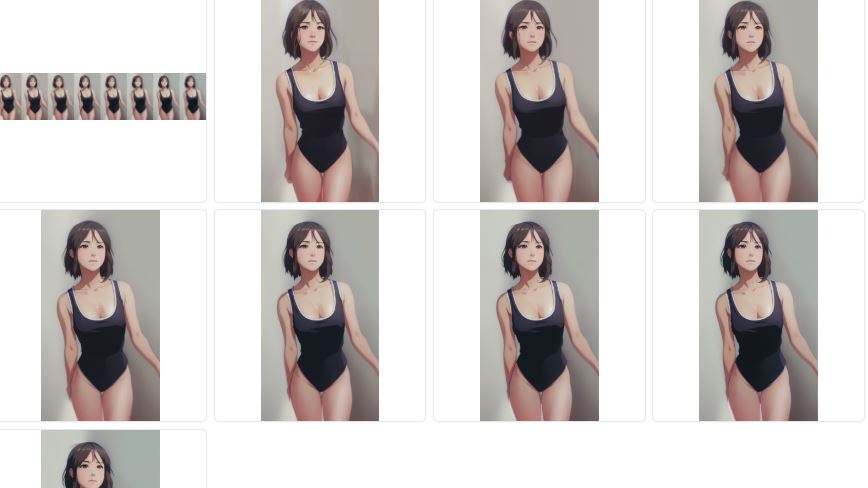
Did you allow the script to control the extension in Settings/ControlNet? You need to enable the option and do a complete restart of A1111 UI, as it seems to set the permissions on startup. Had the same problem, doing that made it work for me.
yeah option was already enable, I figure out is related with denoise strenght.
Try to select "input frame" at last option
input frames, gave me different poses. but I would like to know why previous frame doesn't work for me.
here's another one
In this experiment I used the Dreamshaper model that generates pretty nice illustrations. The ControlNet 'depth' alone, however, is not so great. As we can see it struggles with the details when the fingers are near the mouth and so the AI starts to create a horrible act of chewing finger nails.
Looks great! I think the best method would be if you used something like blender and had it render perfect depthmaps instead of using the preprocessor, but I haven't actually tested that yet. I have heard a lot about https://toyxyz.gumroad.com/l/ciojz for that kind of thing but I have never tried it myself and I don't know how it would work for animations. I would like to implement the ability to add multiple controlnet inputs rather than just the guiding frames but the issue is that, as far as I'm aware, I can only change the "control_net_input_image" property to impact them all at once and I cannot set them individually with a script.
thank you, I will have a look at the Character bones thing.
and sd-webui-controlnet has an API that allows you to target individual ControlNet models:
https://github.com/Mikubill/sd-webui-controlnet/wiki/API
example is here: https://github.com/Mikubill/sd-webui-controlnet/blob/main/scripts/api.py
I figured out my problem. I run Automatic1111 on a Windows machine, to utilize the fast Nvidia card, but my main machine is a Mac, so I have Automatic1111 set to listen mode. When trying to run the script from my Mac it only ever processes the first frame. If I run the script on the actual Windows machine, everything is fine. Keep up the great work, this is cool!
Keep working on it! I like the concept.
Running on a mac m2 was 48 minutes for 16 images.
Any tips to improve speed, other then buy a computer with nvida gpus are welcome.
Even I struggle with speed on it. I plan to upgrade my GPU but I dont see why someone couldnt bring this to their google colab or runpod or anything else like that to run it remotely on faster hardware
Quick tutorial about the script:
Thanks you !!
There is some progress. The settings used are listed below
Looks awesome! What do you have set in the top half of img2img?
Did you put the stylized frame into img2img? Or the just the original one?
first styled it, then sent it to img2img as described in "Step 2"
Ok, thanks!
This is incredible, Xanthius singlehandedly created a far better product than gen-1 from runaway and they have like a team of researchers... I bet they are copying that Idea right now!
Thanks! That's big praise, especially for a project that has currently only taken 3 and a half days to develop. There's still a long way to go with this
Here's my first working test. I used ~50 frames of my little brother walking on all fours towards the camera.
Thank you so much for this :)
Hey! Looks great! What setting did you use? Denoise strnght, ControlNet setting and script settings. I am trying for 2 days without success... I would really appreciate some help:) Thanks!
Hi!
I sent my img2img render of the first frame to img2img.
- img2img Denoising 0.95
- ControlNet 'depth' (+preprocessor depth) with default settings
- script settings: init denoise=1, Third Frame Img=FirstGen, Color Correction On, Loopback Source=Previous Frame
- prompt: a chimpanzee walks through the desert
I upload a sequence of 512x512 images - there's no visual feedback, yet. So it's just a 'trust me bro' thing for now ;)
Don't put anything in the ControlNet image upload - this is where the script puts your frames automatically.
Make sure that the mentioned ControlNet setting is enabled that allows the script to control the extension.
Thanks a lot, man! I'll try your settings
And what is your loopback source?
Yeah what you put in loopback source ? when I use previous frame it's keep the same frame for each render :/
Had the same issue. It was working after I restarted A1111 completely (not just 'reload ui') and checked 'Allow other script to control this extension' again - it was unchecked after the restart. So maybe your script just does not have the permission (yet) to drop the frames into ControlNet.
Loopback Source=Previous Frame
I edited my post above for completeness ;)
Thanks for the helps !
TY!!
Ok I make it work !!!
The problem was in the settings tab for COntrolNEt. There is a checkbox:
Allow other script to control this extension
You need to check it and work perfectly. Thank you for your great job !
oh yeah, without that my script can't change the ControlNet image. Glad you got that fixed and if someone else has the issue I know what to suggest
I can't get it work even with this option activate :/ can you make a youtube tutorial please !
For me it worked after shutting A1111 off completely and I also rebooted my machine.
Hi it's awesome but can you post pictures of all your settings please ? thanks
That looks like far too low of a ControlNet strength. You can see the comparison in the post using Snape
Heres my settings. Idk what Iam doing wrong ? It can be something related to my settings for ControlNet ?
I see. I havent really been testing much with multi-ControlNet for the sake of speed, but I'm guessing that it would come down to the weights for the two controlnet layers. This tool is still extremely early so a lot of testing needs to be done to figure out the best way to get the right results.
Do you think, you could make a quick tuto on youtube for us plz ?
There are a few youtubers who have said they are working on tutorials for it. It has only been published for around 2 days, so many things aren't fully worked out or understood yet, even by me, so they may take a bit of time to experiment and figure it out for the models and embeddings they may use it with then publish their video. Each model seems to need different settings
I will try only one ControlNet and RealisticVision 1.3.
Do you use HED for ControlNet ?
I use HED, openpose, depth, or canny depending on the image but I nearly always test on RealisticVision1.4
And when you generate with img2img. Do you remove the first image in ControlNet ?
Also, is there a format for the name of the guide frames ? yours is like xxxx01_00, xxxx02_00 ?
Maybe it is why it doesn't follow my animation ?
the animations should just be in alphabetical order but it doesnt need a specific naming scheme. It could be causing your problem though. I never put anything into the controlNet input manually. I just leave the image sections blank on those and let it get auto-filled
I'm having the same trouble as finefin – just rendering after rendering of the first frame – and I've still got the problem of it rendering 3-up strips, even after installing v.72. Should there be some feedback in the GUI after I upload my images? It doesn't show if they've uploaded or not. I've tried both Safari and Chrome on a Mac. This looks like an amazing achievement! Excited to get it working!
The images are not uploading and not showing up in the gui. I end up with 'animations' of one single image. Images are 512x512 and named image001.png, image002.png etc. What am I missing?
Are you talking about the upload of the guide frames? At the moment the UI doesn't give visual feedback on that, but I would like to add something to show that the files were successfully uploaded (perhaps a number indicating how many frames are currently uploaded)
As for the image outputs, the individual frames should appear in the "stable-diffusion-webui\outputs\img2img-images" folder and should be named along the lines of "Frame-0001" and the spritesheets should be saved to "stable-diffusion-webui\outputs\img2img-grids" with names such as "grid-0001" although the filename for this is subject to change in future updates.
Both the spritesheet and the individual frames should properly output to the GUI and do on my end. Does nothing get returned for you or what exactly are you getting?
ah ok, no visual feedback for the upload, yet. noted.
the single images+grid are saved, but they all are based on the first frame. I checked 'allow other scripts to control' in the settings as well.
EDIT: hah! it works! I just rebooted my machine and now it just works. Will upload a sample gif later ;)
I look forward to seeing your results!
I have put the script on SD scripts directory but i see nothing in scripts UI box
Reload ui and it's for img2img only.
In fact, it appears on the im2img tab, it's ok
Can we call the midas depth information tool to mask the generation of background? Only generate characters
My image seem to get darker and darker until they disappear completely.
something like this:https://drive.google.com/file/d/1BD00eeoX6AL2zfgOThYaBpKDWU8pf-OQ/view?usp=share..
the image you linked requires permission to view but that issue largely comes down to settings such as denoise strength, ColorCorrection, and Third Frame Image.
oh, i found it. needs to be checked "Settings: Apply color correction to img2img results to match original colors."
one more question, where can i get the sprite sheet and the frames. The images I get are three stitched together, I don't know if this is normal.
It should directly output the spritesheet and the frames. You're the second person to have it output the 3-panel images instead and I'm not sure why some people have that happen
I actually have that problem too, was very excited to test this but yeah, also getting that 3 panels.
me too...Is there anything wrong with the recommended parameters in the screenshot above, or what did I miss?
I have the same problem, so I getting just the panels and not the single frames.
New Version (0.72) should fix the 3-panel issue.
The individual files should be named along the lines of Frame-XXXX and will be located in your default folder for images. The spritesheet will be in the default folder for grids
Here's a gif I generated while writing and testing the fix:
Shelon Musk
im getting this any idea why ?? and is control net suppose to be on the same wauy in the img2img page ? can you show pics of both setups as pics the whole page ?
TypeError: object of type 'NoneType' has no len()
Time taken: 0.00s
Torch active/reserved: 2765/3164 MiB, Sys VRAM: 5696/24576 MiB (23.18%)
the "object of type 'NoneType' has no len()" error usually occurs if you forgot to give it the animation guide frames.
To provide the guide frames for the script, press the "Upload Guide Frames" button located just above the slider and select the frames of your animation
Ok i didnt understand how to make those frames , i didnt really get from your instruction where u say how to make them , what part is itn?
If you have the frames from a guiding video then you can put those in. It's just the input for ControlNet, so you could also put in a processed set of images for your choice of model (openpose, hed, depth, etc...) with the preprocessor disabled.
This looks awesome, gonna try it out with the anythingv3 model
Looks great! I follow your instructions but only background is changing. What coluld be the problem?
My guess would be the controlnet settings. Check how your controlnet mask looks when only working with the first frame to get an idea of what may be wrong and what it's picking up. Perhaps pick a different controlnet model or just fix the settings on the one you are using.
Thank you for your fast response. I tride different ControlNet models (canny, hed, depth, normal), weight (0.3,0.5,0.9 or even 1.6), preprocessor on/off and 3 sets of guide frames with no luck. Only this happens:
What does the original video look like? it's hard to keep a consistent background unless the original background has enough detail to be picked up with ControlNet. For that reason I expect many people will just generate with a greenscreen or something then superimpose it onto a background.
Sorry, I didn't specify. The background is not a problem. The face is not moving no matter what is on the source video
how many frames did you upload for it? and what did they look like?
as someone else stated:
"The problem was in the settings tab for ControlNet. There is a checkbox:
Allow other script to control this extension"
If you dont have this enabled on the A1111 settings page under the ControlNet Tab then the script wont be able to update the controlnet image
That was it! Thank you very much!
Now that's looking great!
Also this needs a name, it would make things easy to search what people can make with this on internet.
It sure does, I just suck at naming. In the future I plan to make a much better and more robust animation tool based on this which will probably be an extension instead of just a script and I intend to call that one Xanimate (combining my screen-name and the world Animate) which I think it at least better
I think Xanimate is awesome, you could add AI in the end to distinguish it or something if needed, but Xanimate is great!
This is crazy!!!
I thought that kind of coherence between frames would require an entirely new iteration of stable diffusion. I never thought this would be possible by a single person, this is huge! And you didn't even use denoising post production tricks to achieve that ... that's like 500 IQ move! 😄 well done!
Hey cool tool I have a RTX 3090 if you ever wanted to test stuff out over zoom or discord -